1 准备工作
1.1 关闭虚拟内存
通过下面的命令临时关闭虚拟内存
swapoff -a通过修改配置文件可以永久关闭虚拟内存
vi /etc/fstab
#注释这个文件中类似下面的代码
/swap.img none swap sw 0 01.2 关闭防火墙
通过下面的命令可以关闭防火墙
ufw disable1.3 配置时间服务,保证时间同步
timedatectl set-timezone Asia/Shanghai
#执行后重启服务
systemctl restart systemd-timesyncd.service
#通过
timedatectl status
# 或者
date
#查看时间服务是否已经正确设置1.4 配置hostname
#按照自己的配置替换即可
echo "192.168.0.110 k8s-3" | sudo tee -a /etc/hosts1.5 开启路由转发
开这个的原因是让各个主机承担起网络路由的角色,因为后续还要安装网络插件,要有一个路由器各个 Pod 才能互相通信。执行:
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.ipv4.ip_forward = 1
EOF
#应用参数
sudo sysctl --system
#查看结果
sysctl net.ipv4.ip_forward2 安装并配置containerd
2.1 安装
这里仅介绍通过包管理器安装的方式,通常通过包管理器安装的版本会落后几个版本,但是相对稳定
通过下面的命令安装containerd
apt update && apt install -y containerd2.2 生成配置文件
通过下面的命令可以为containerd生成对应的配置文件.
sudo mkdir -p /etc/containerd && \
sudo containerd config default > /etc/containerd/config.toml
修改/etc/containerd/config.toml 文件中:
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc] 下 [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options] 下的 SystemdCgroup 为 true修改这个配置是因为kubelet和底层容器运行时(我们用的是containerd)都需要对接控制组来强制为Pod和容器管理资源,并且运行时和k8s需要用同一个初始化系统,Ubuntu默认使用的初始化系统是systemd,k8s v1.22起,如果没有在KubeletConfiguration下设置cgroupDriver字段,kubeadm默认使用systemd,所以我们只需要设置containerd就行了。
如果需要配置镜像源,可以先参考下一节配置镜像源,然后再执行重启。
2. 配置containerd镜像源
我们使用containerd作为底层的容器管理平台,为保证后续顺利拉取镜像,需要给containerd配置镜像源(如果机器或网络已经配置代理,请忽略本项)
containerd支持在/etc/containerd/config.toml配置文件中直接配置,但是在高版本(版本号大于等于1.5)新增了通过额外配置文件的方式配置镜像源,因此这里不再介绍低版本的配置方式。
首先我们需要创建目录mkdir /etc/containerd/certs.d/,后续我们所有的镜像网站都会配置在这个目录下,由于本次是配置容器镜像的代理网站,因此创建docker.io目录,整体执行命令如下:
mkdir /etc/containerd/certs.d/
mkdir /etc/containerd/certs.d/docker.io
vim /etc/containerd/certs.d/docker.io/hosts.toml
//导入文件的内容
[host."https://docker.1ms.run"]
capabilities = ["pull","resolve"]在完成配置文件的编写后,请通过sudo sed -ri 's@(config_path).*@\1 = "/etc/containerd/certs.d"@g' /etc/containerd/config.toml命令将配置文件路径导入到/etc/containerd/config.toml中。
需要注意的是,配置完成后,需要执行systemctl restart containerd命令重启containerd服务,以保证服务生效。
在创建容器时,如果发现部分容器迟迟卡在creating状态或拉取镜像的状态,请通过kubectl get event -A命令查看是否是因为无法通过docker.io拉取镜像,如果是,请按照上面的步骤配置镜像源
3. 安装 kubeadm、kubelet、kubectl
kubeadm 是自动引导整个集群的工具,本质上 k8s 就是一些容器服务相互配合完成管理集群的任务,如果你知道具体安装哪些容器那么可以不用这个。 kubalet 是各个节点的总管,它上面都管,管理Pod、资源、日志、节点健康状态等等,它不是一个容器,是一个本地软件,所以必须得安装 kubectl 是命令行工具,给我们敲命令与 k8s 交互用的,必须得安装
通过下面的命令更新数据源
sudo apt update && \
sudo apt upgrade -y3.1 安装依赖
通过下面的命令安装一些依赖库
sudo apt install -y apt-transport-https ca-certificates curl gpg创建k8s的密钥管理目录:
sudo mkdir -p -m 755 /etc/apt/keyrings下载k8s的密钥,并导入到本地目录
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.30/deb/Release.key | \
sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg && \
sudo chmod 644 /etc/apt/keyrings/kubernetes-apt-keyring.gpg添加k8s的apt目录
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.30/deb/ /' \
| sudo tee /etc/apt/sources.list.d/kubernetes.list更新 apt 索引,并且安装,还要防止软件更新,三步:
sudo apt update && \
sudo apt install -y kubelet kubectl kubeadm && \
sudo apt-mark hold kubelet kubeadm kubectl通过下面命令启动服务,并设置为开机自启动
sudo systemctl enable --now kubelet4. k8s init(只在master节点执行即可)
使用的相关版本:
k8s:1.30.11
ubuntu:22.04
可以提前拉取配置镜像
sudo kubeadm config images pull \
--kubernetes-version=v1.30.1 \
--cri-socket=unix:///run/containerd/containerd.sock \
--image-repository=registry.aliyuncs.com/google_containers \ # 觉得慢加上这个我们可以执行一个类似下面的命令来初始化k8s:
sudo kubeadm init --apiserver-advertise-address=192.168.0.108\
--control-plane-endpoint=k8s-master\
--kubernetes-version=v1.30.1\
--service-cidr=10.50.0.0/16\
--pod-network-cidr=10.60.0.0/16\
--cri-socket=unix:///run/containerd/containerd.sock\
--image-repository=registry.aliyuncs.com/google_containers命令中参数的含义如下:
control-plane-endpoint:表示控制屏幕位于哪个节点,这里可以使用在hosts文件配置的名称,也可以直接配置ip
这里表示
如果需要重新创建,那么需要执行下面的命令来重置k8s的init状态
sudo kubeadm reset # 重置 kubeadm ,执行这个后需要敲 y 回车
sudo rm -rf /etc/cni/net.d # 删除上次 init 生成的文件
sudo rm -rf /var/lib/etcd # 删除上次 init 生成的文件kube-init执行完成后会输出类似的结果:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join k8s-master:6443 --token syyy90.ttatwd4p11lju3gq \
--discovery-token-ca-cert-hash sha256:9b85798b6b46b599027b14f902834d55505a9e71115d987ef88bf175af1b49db \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join k8s-master:6443 --token syyy90.ttatwd4p11lju3gq \
--discovery-token-ca-cert-hash sha256:9b85798b6b46b599027b14f902834d55505a9e71115d987ef88bf175af1b49db 如果不是 pause:3.8 ,那就是镜像拉取失败,可能是没有指定国内的源去国外下载失败了,需要指定国内的源并提前拉取镜像;
还有可能是我们指定的源(比如阿里源)没有这个镜像,因为 k8s-v1.30.1 这个版本会默认使用 3.8 版本的沙箱,不知道什么原因拉取不下来这个镜像,所以只能拉取 3.9 下来改为 3.8:
ctr --namespace k8s.io image pull registry.aliyuncs.com/google_containers/pause:3.9 ctr --namespace k8s.io image tag registry.aliyuncs.com/google_containers/pause:3.9 registry.k8s.io/pause:3.8
5. 安装网络插件 Calico
执行完成之后需要安装网络插件才能与集群中的其他节点通信
wget https://raw.githubusercontent.com/projectcalico/calico/v3.28.0/manifests/tigera-operator.yaml
#或者
curl -O https://raw.githubusercontent.com/projectcalico/calico/v3.28.0/manifests/tigera-operator.yaml下载完成这个配置文件之后,应该执行:
kubectl create -f tigera-operator.yaml
curl -O https://raw.githubusercontent.com/projectcalico/calico/v3.28.0/manifests/custom-resources.yaml
kubectl apply -f custom-resources.yamlcustom-resources.yaml之间
执行完成之后
安装完成之后,pod列表中就会出现一个类似这种的,等到列表中的数据全部就绪之后,就可以开始初始化非控制节点,并将其加入集群当中。
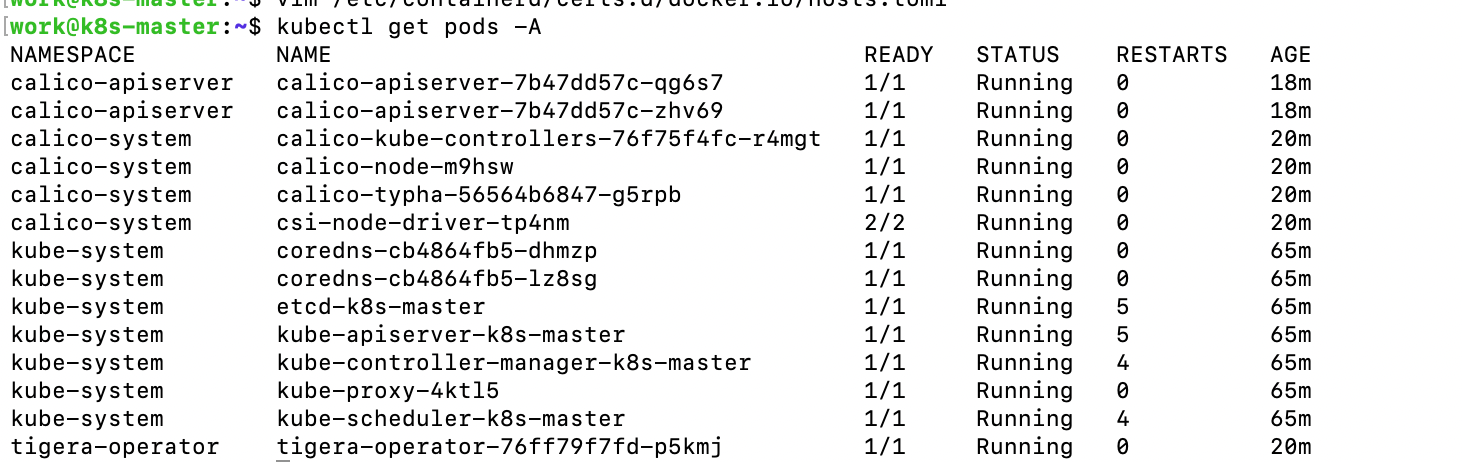
6. 非控制节点加入集群加入集群
节点需要加入集群时,直接按照控制节点初始化完成之后的执行命令执行即可,如果节点不是控制节点,那么就移除最后的参数。
执行命令之后,我们可以看到下面的输出
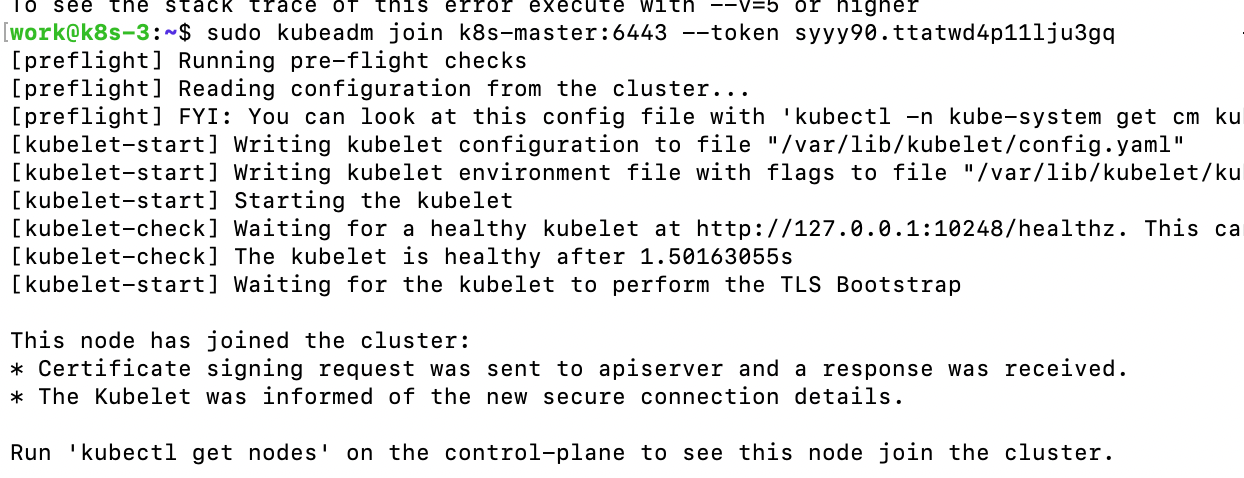
在主节点看到所有pod都恢复到running状态之后,即为执行成功。